[Scala] Water Pouring 문제
26 Feb 2023들어가며
내가 듣고 있는 Coursera Scala 강의에서 그동안 배웠던 내용의 총정리 개념으로 Water Pouring Puzzle을 풀어보는 수업이 있었다. 관련 내용을 정리하기 위해 포스트를 작성하게 되었다. 이미 지난 class, lazy evaluation에 대한 포스트를 통해 class와 lazy evaluation에 대한 내용은 정리를 하였고, 다시 수업의 처음부터 정리하면서 그 동안의 개념을 복습해 볼 예정이다.
Water Pouring Puzzle

Water Pouring Puzzle은 학창시절에 다들 한 번 씩은 봤을 만한 문제이다. 눈금이 없는 2개 이상의 물통을 통해 특정한 양의 물을 얻는 방법을 알아내는 문제이다.
예를 들어, 눈금 없는 4L의 물통과 7L의 물통이 있을 때 6L의 물을 얻는 방법을 생각해보자.
- 7L의 물통에 물을 가득 채운다. (4L 물통 - 0L, 7L 물통 - 7L)
- 4L의 물통으로 7L 물통의 물을 퍼낸다. (4L 물통 - 4L, 7L 물통 - 3L)
- 4L 물통의 물을 버린다. (4L 물통 - 0L, 7L 물통 - 3L)
- 7L 물통의 물을 4L 물통으로 옮긴다. (4L 물통 - 3L, 7L 물통 - 0L)
- 7L 물통을 채운다. (4L 물통 - 3L, 7L 물통 - 7L)
- 7L 물통의 물을 4L 물통이 다 찰 때까지 비우면 7L의 물통에는 6L의 물이 남는다. (4L 물통 - 4L, 7L 물통 - 6L)
이번 포스트에서는 스칼라를 통해 이 퍼즐을 풀어볼 것이다.
Class
class WaterPouring(cap: Vector[Int]) {
type Status = Vector[Int]
val initialStatus = cap map (x => 0)
...
}
강의의 코드는 위와 같이 Vector[Int] 타입의 cap 인자를 받으면서 WaterPouring 클래스를 선언하는 모습이다. 여기서 cap는 사용할 물통들의 용량을 뜻한다. 클래스에 대한 내용은 이전 포스트를 참조 해주길 바란다.
다음 줄에서는 type 키워드를 통해 클래스 안에서 쓰일 타입을 선언하고 있다. Vector[Int]를 Status 타입으로 선언하였다. 이런 식으로 타입을 선언해 두면 어떤 때 이 타입을 사용하는지 명확하게 표현할 수 있다.
다음 줄에서는 initialStatus를 초기화 하고 있다. map 메서드를 통해 cap의 크기만큼의 0으로 된 Vector[Int]를 만들고 있다. 이후에 나오는 코드들은 모두 WaterPouring 클래스 안에 들어있는 내용이다.
Trait과 Case Class
// Moves
trait Move {
def change(status: Status): Status
}
case class Empty(bucket: Int) extends Move {
def change(status: Status): Status = status.updated(bucket, 0)
}
case class Fill(bucket: Int) extends Move {
def change(status: Status): Status = status.updated(bucket, cap(bucket))
}
case class Pour(from: Int, to: Int) extends Move {
def change(status: Status): Status = {
val amount = status(from) min (cap(to) - status(to))
val fromStatus = status.updated(from, status(from) - amount)
val toStatus = fromStatus.updated(to, status(to) + amount)
toStatus
}
}
다음에는 trait과 case class를 통해 Water Pouring Puzzle에서 필요한 동작들을 선언하고 있다. 위 예제와 같이 trait 혹은 abstract class와 case class의 조합을 통해 계층구조를 쉽게 표현할 수 있다.
trait은 자바의 interface와 비슷하지만, 하나의 클래스는 하나의 interface만 상속받을 수 있는 것과 달리 스칼라에서는 하나의 클래스가 두 개 이상의 trait을 상속받을 수 있다.
scala> trait trait1
// defined trait trait1
scala> trait trait2
// defined trait trait2
scala> class class1 extends trait1, trait2
// defined class class1
공식 문서에 따르면, case class는 다음과 같은 특징을 가지는 일반 클래스라고 한다.
- 기본적으로 불변
- 패턴 매칭을 통해 분해가능
- 레퍼런스가 아닌 구조적인 동등성으로 비교됨
- 초기화와 운영이 간결함
위에서 말했다시피, case class와 trait을 쓰면 계층 클래스 구조를 쉽게 표현할 수 있다. 다음은 trait과 case class를 통해 fruit 종류를 표현하는 예제이다.
scala> trait fruit
// defined trait fruit
scala> case class apple() extends fruit
// defined case class apple
scala> case class strawberry(name: String) extends fruit
// defined case class strawberry
scala> case class kiwi(name: String, grade: Int) extends fruit
// defined case class kiwi
case class에서는 일반적인 class와는 달리 클래스를 선언할 때 꼭 인자 목록을 넣어줘야 한다(비어 있어도 가능).
scala> case class pear extends fruit
-- [E004] Syntax Error: --------------------------------------------------------
1 |case class pear extends fruit
| ^^^^
| A case class must have at least one parameter list
|
| longer explanation available when compiling with `-explain`
1 error found
scala> case class pear() extends fruit
// defined case class pear
원래 예제에서, status.updated(a,b)라는 메서드를 사용하고 있다. status는 이전에 선언했던 Status 타입, 즉 Vector[Int] 타입의 객체이다. updated 메서드는 Vector 클래스의 내장 함수로, a번째 요소를 b로 바꾸는 메서드이다.
scala> val vector1: Vector[Int] = Vector[Int](1,2,3,4,5)
val vector1: Vector[Int] = Vector(1, 2, 3, 4, 5)
scala> vector1.updated(2, 0)
val res0: Vector[Int] = Vector(1, 2, 0, 4, 5)
원래 예제를 다시 보자. Move trait을 선언하면서 이 trait을 상속받는 클래스들은 Move의 하위 클래스라는 것을 알려주고 있다. 또 change라는 abstract method를 통해 하위 클래스들은 change를 구현해야 함을 알려주고 있다.
Empty 클래스는 bucket 번째 물통을 비우는 클래스이다. Empty는 Move를 상속받고, bucket 라는 Int 타입의 객체를 입력 받으면서 현재 물통 상태인 status 객체의 bucket 번째 값을 0으로 만든다.
Fill 클래스는 bucket 번째 물통을 채우는 클래스이다. Fill은 bucket를 입력 받아 status의 bucket 번째 값을 bucket의 용량 만큼 채운다.
Pour 클래스는 from 번째 물통에서 to 번째 물통으로 물을 옮기는 클래스이다. from과 to를 입력받아 (from 번째 물통의 현재 물의 양)과 ((to 번째 물통 용량) - (to 번째 물통의 현재 물의 양))을 비교하여 더 적은 양을 from 번째 물통에서 빼고 to 번째 물통에 넣는다. 예를 들어 4L 물통에 물 4L가 담겨있고 7L 물통에 물 4L가 담겨 있는 상태에서 4L 통에 있는 물을 7L 통으로 옮기면 7-4=3L의 물을 4L 통에서 빼서 7L 통으로 옮긴다. 결국 4L 통에는 4-3=1L가 남고 7L 통에는 7L 가 채워진다.
동작 생성
val buckets = 0 until cap.length
val emtpyMoves = for (b <- buckets) yield Empty(b)
val fillMoves = for (b <- buckets) yield Fill(b)
val pourMoves = for {
from <- buckets
to <- buckets
if from != to
} yield Pour(from, to)
val allMoves = emptyMoves ++ fillMoves ++ pourMoves
각 bucket에 대해, empty, fill, pour 동작에 대한 모든 경우의 수를 구하고 allMoves라는 변수에 저장한다. collection은 ++ 연산으로 쉽게 더할 수 있다.
결과는 다음과 같이 생성된다.
val problem = new WaterPouring(Vector(4, 9))
problem.allMoves
// res0: IndexedSeq[Move] = Vector(Empty(0), Empty(1), Fill(0), Fill(1), Pour(0,1), Pour(1,0))
Path
class PathOrigin(history: List[Move]) {
def endStatus: Status = trackStatus(history)
private def trackStatus(xs: List[Move]): Status = xs match {
case Nil => initialStatus
case move :: xs1 => move.change(trackStatus(xs1))
}
def extend(move: Move) = new PathOrigin(move :: history)
override def toString = (history.reverse mkString " ") + "-> " + endStatus
}
val initialPath = new PathOrigin(Nil)
Path는 동작(Move)들의 Sequence이다. 즉 동작들을 연속적으로 수행하는 것이 Path이다. 이 강의에서는 가장 마지막 move가 path의 맨 앞으로 오도록 했다. 위 클래스에서, endStatus는 path의 모든 동작들을 시킨 후의 결과 status이다. 그 동작들을 수행하는 메서드는 trackStatus 이다.
trackStatus는 Move의 List를 입력받아 List에 저장된 Move들을 수행한 후의 최종 status를 반환한다. 이 메서드는 pattern matching으로 구현되어 있다. xs가 Nil이면 initialStatus를 반환하고, List 형식이면 List의 첫 번째 요소의 change 메서드를 뒤 요소 List의 결과물을 입력받아 실행한 결과물을 반환한다. 이 메서드는 재귀적으로 수행되어 요소가 Nil일 때까지 반복한다. 이 메서드가 수행되는 모습을 그림으로 표현하면 다음과 같다.
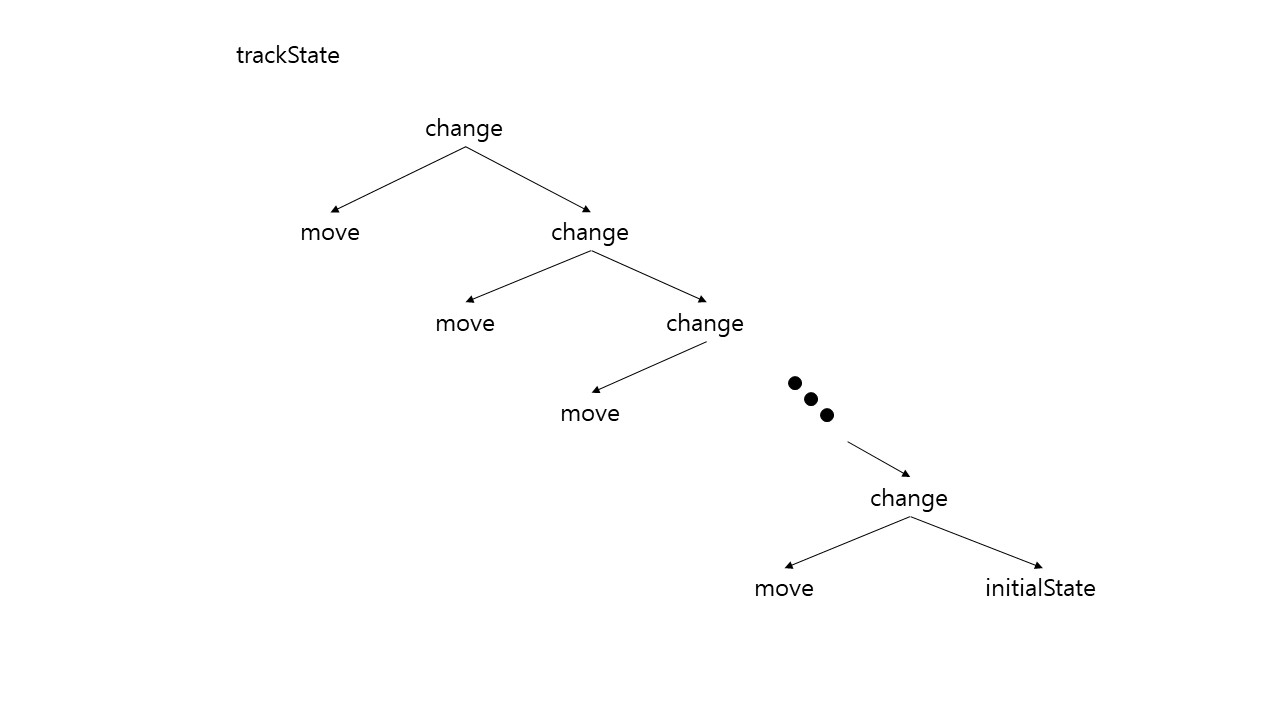
논리적으로, initialStatus에서 시작하여 처음 move의 change 연산부터 순차적으로 수행되어, 각 change 연산이 수행되어 생성되는 status들이 결합되어, 마지막으로 xs의 head move의 change 연산이 수행되어 endStatus를 반환하게 된다.
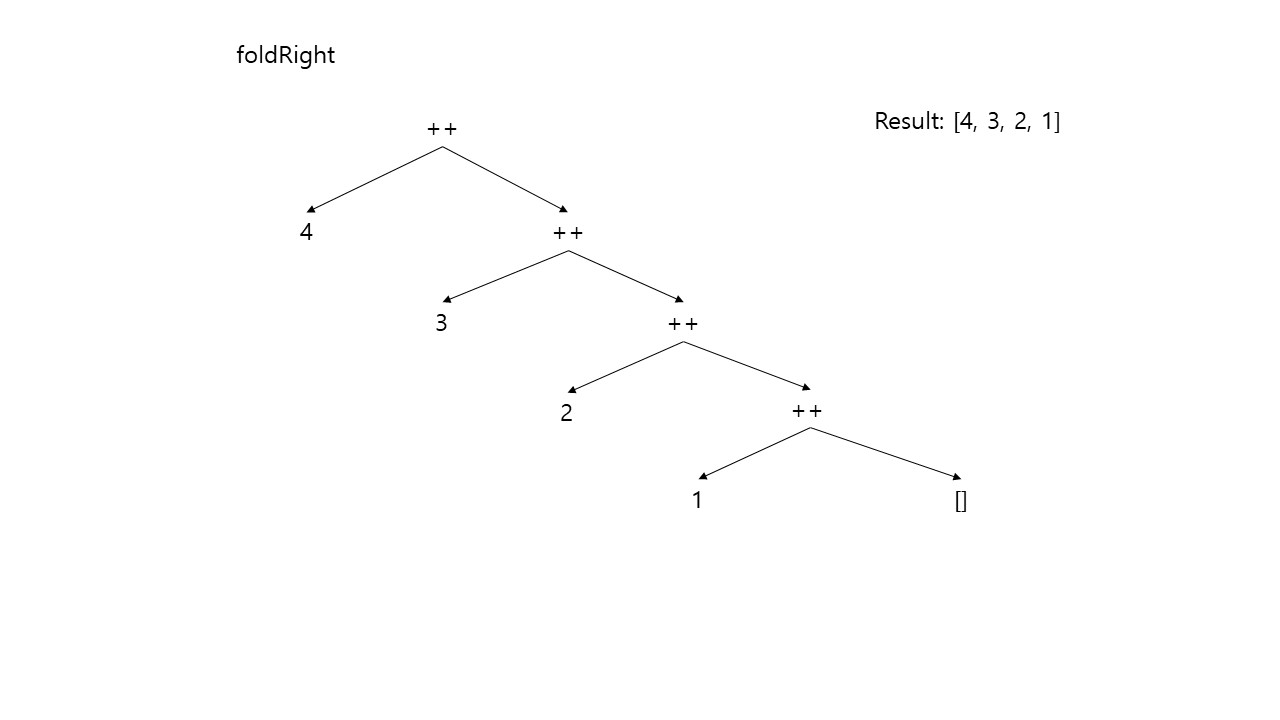
그런데 이것을 간단히 수행할 수 있는 메서드가 있다. 바로 foldRight 메서드이다. 위와 같이 데이터 구조를 합칠 수 있는 연산의 재귀적 호출을 통해 최종 결과 데이터 구조를 반환하는 함수를 fold 함수라 하는데, 위의 경우는 오른쪽에서 위로 올라오므로 foldRight 함수이다.
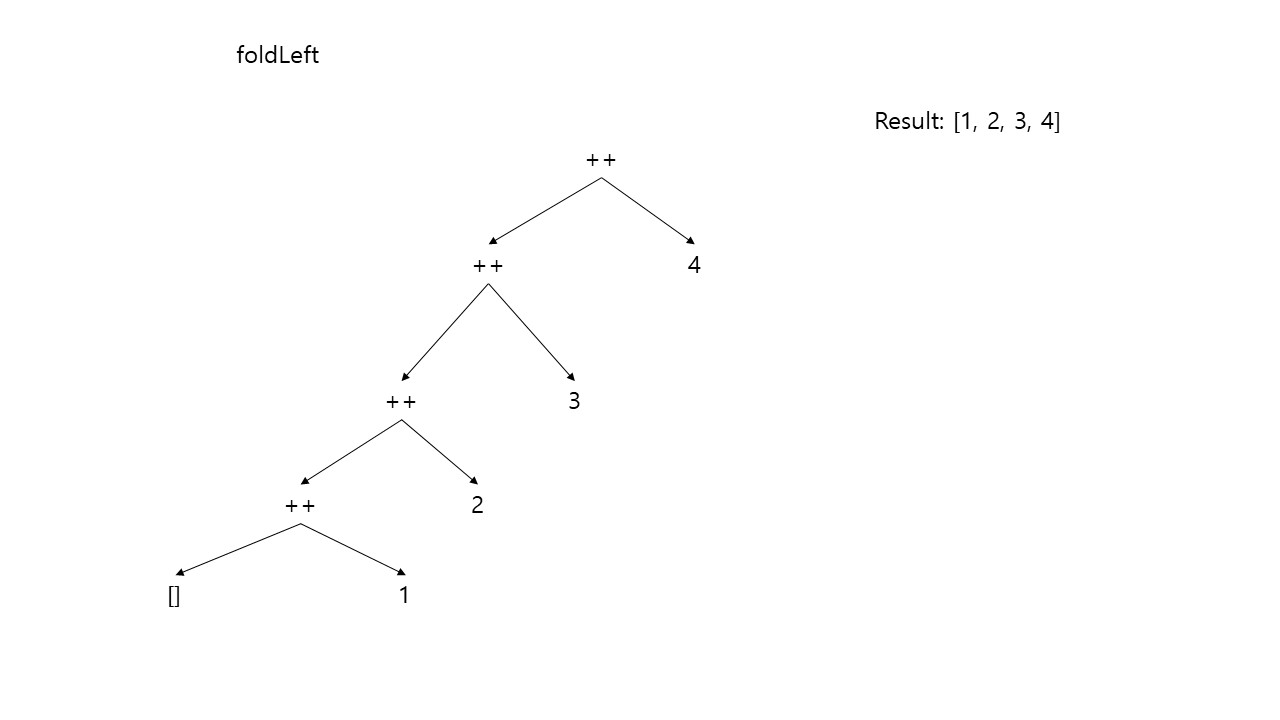
반대로 왼쪽에서 위로 올라오는 fold 함수를 foldLeft 함수라 한다.
위의 endStatus를 foldRight 메서드를 통해 구현해보자. 초기 값은 initialStatus이고, history List를 맨 뒤부터 change 메서드를 순차적으로 수행하여 List를 결합하고 마지막으로 List의 head의 change를 수행하며 endStatus를 반환한다. 이 것을 다음과 같이 구현할 수 있다.
val endStatus: Status = (history.foldRight(initialStatus)) (_ change _)
위와 같이 fold 메서드를 통해 간단히 구현이 가능하다.
아래 extend 메서드는 기존의 path에 새로운 동작을 추가한 새로운 path를 반환하는 메서드이다. 이 메서드로 경로를 확장할 수 있다. 그리고 toString 메서드를 구현하고 initialPath를 설정하였다.
그런데 path를 이런 식으로 구현하면 extend 할 때마다 endStatus의 계산을 history를 이용하여 처음부터 다시 해야 된다는 문제점이 생긴다. 이렇게 되면 경우의 수가 조금만 늘어나도 연산 양은 기하급수적으로 늘어나게 된다. 이럴 때는 현재 상태를 넣어서 현재 상태에서 새로운 move만 수행하여 새로운 path를 구하는 형식으로 구현할 수 있다.
class Path(history: List[Move], val endStatus: Status) {
private def trackStatus(xs: List[Move]): Status = xs match {
case Nil => initialStatus
case move :: xs1 => move.change(trackStatus(xs1))
}
def extend(move: Move) = new Path(move :: history, move.change(endStatus))
override def toString = (history.reverse mkString " ") + "-> " + endStatus
}
val initialPath = new Path(Nil, initialStatus)
위와 같이 Path에 현재 endStatus를 넣고, extend를 수행하면 history 앞에 move를 추가하고, 입력 받았던 endStatus에 move를 수행한 최종 상태를 입력해 새로운 Path를 생성한다.
경로 모음
def from(paths: Set[Path], explored: Set[Status]): LazyList[Set[Path]] = {
if (paths.isEmpty) LazyList.empty
else {
val tailElem = for {
path <- paths
next <- allMoves.map(path.extend)
if !(explored contains next.endStatus)
} yield next
paths #:: from(tailElem, explored ++ (tailElem.map(x => x.endStatus)))
}
}
val pathSets = from(Set(initialPath), Set(initialStatus))
이제 경로의 모든 경우의 수들을 계산하여 저장해 보자. from 메서드는 Path의 집합과 Status들의 집합을 입력받아 Path의 집합의 LazyList를 반환하고 있다. LazyList는 immutable linked list로, 선언된 순간에 리스트가 생성되는 것이 아닌, 리스트 안의 요소들이 필요한 순간에 계산된다. LazyList에 대한 내용은 지난 포스트에서 정리하였다.
from 메서드는 가능한 모든 path들이 조합을 LazyList 형태로 생성하는 메서드이다. 입력받은 path Set과 status Set에서 시작하여 path의 경우의 수를 무한히 생성하는 메서드이다. 이전의 path Set들에 가능한 동작을 수행하여 새로운 path Set을 생성한다. 중복되는 status는 추가하지 않는다. pathSet는 initialPath와 initialStatus에서 시작하여 가능한 path 경우의 수를 저장하는 LazyList이다. 이 pathSet의 요소들을 사용하는 순간 평가된다.
paths #:: from(tailElem, explored ++ (tailElem map (_.endStatus))) 부분을 보면, 무한히 from 메서드의 결과를 붙이는 것을 알 수 있다. 일반 List라면 무한하기 때문에 불가능하지만 LazyList는 필요한 요소만 평가하기 때문에 from 메서드를 사용할 수 있다.
pathSet을 직접 사용해 보면 다음과 같다.
val problem = new WaterPouring(Vector(4, 7))
problem.pathSets.take(2).toList
res1: List[Set[Path]] = List(Set(-> Vector(0, 0)), Set(Fill(0)-> Vector(4, 0), Fill(1)-> Vector(0, 7)))
pathSet의 2 번째 요소까지 잘 가져오는 것을 확인할 수 있다.
Solution
def solutions(target: Int): LazyList[Path] =
for {
pathSet <- pathSets
path <- pathSet
if path.endStatus contains target
} yield path
정답을 찾는 메서드는 간단하다. 타겟 정수를 입력 받고, pathSet의 endStatus에 타겟 정수가 있으면 그 path를 반환한다. 사용해보면 다음과 같다.
val problem = new WaterPouring(Vector(4, 7))
problem.solutions(6).toList
res2: List[Path] = List(Fill(1) Pour(1,0) Empty(0) Pour(1,0) Fill(1) Pour(1,0)-> Vector(4, 6), Fill(1) Pour(1,0) Empty(0) Pour(1,0) Fill(1) Pour(1,0) Empty(0)-> Vector(0, 6))
6을 얻는 path가 잘 나오는 것을 확인할 수 있다.
마치며
Water Pouring Puzzle을 통해 그동안 스칼라에 대해 배웠던 내용이 잘 정리된 느낌이다. 강의를 들으면서 스칼라 언어가 참 흥미롭기도 하지만, 어려운 알고리즘을 참 쉽게 구현하는 것 같았다. 나도 그 정도의 경지에 오르고 싶다는 생각이 들었다.